In [17]:
clf = LogisticRegression(max_iter=1000,solver='newton-cholesky',class_weight='balanced')
study = LRStudy(clf,X_train,y_train,feat_dict['all'])
study.build_pipeline()
study.plot_coeff(title_add = 'L2-regularization only')

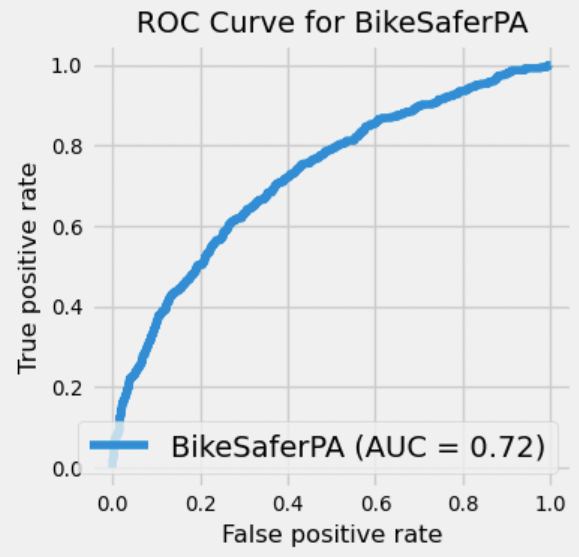
Score on validation set: 0.72338032152522